ACL 2021 | 个性化的Transformer——连接ID和文字,同时生成推荐和解释
Author: Lei LI
Department of Computer Science, Hong Kong Baptist University
- Lei Li, Yongfeng Zhang, Li Chen. Personalized Transformer for Explainable Recommendation. ACL'21. [Paper][Code]
序言
近些年,推荐系统领域的发展常常大量借鉴其他领域的最新技术,比如不久前的CNN和RNN,以及近期的预训练和GNN。反过来,推荐系统自己的特色“个性化”以及核心思想“协同过滤”是否也可以推广到其他领域呢?这篇文章算是我们朝着这个目标迈出的一小步。
摘要
个性化在众多的自然语言生成任务中扮演着至关重要的角色,譬如可解释推荐、用户点评总结以及对话系统。在这些任务中,用户和产品的ID在实现个性化的过程中起到了身份辨识的作用。Transformer被证明拥有强大的语言建模能力,但它却不够个性化,并且难以利用这些ID,因为ID和文字完全不在同一个语义空间上。为了解决这个问题,我们在可解释推荐这个课题上提出了一种个性化的Transformer(PErsonalized Transformer for Explainable Recommendation,简称PETER)。我们设计了一个简单并且有效的任务,即利用ID来预测需要被生成的解释中的单词,从而使ID具有语言学含义,并使Transformer变得个性化。除了生成解释外,PETER还可以做推荐,有效地统一推荐和解释两大任务。大量实验表明,虽然我们的模型规模小,并且没有经过预训练,在性能和效率上均优于经过微调的BERT,从而凸显出了我们整个设计的重要性。
难点
由于用户ID和产品ID起到了区分和辨识不同用户和不同产品的作用。同时,不同用户喜好各异,不同产品也各具特色,因此ID是实现个性化的基石。推荐系统的解释生成问题可以这样定义:给定一个用户ID和一个产品ID,生成一句话来解释为什么这个产品要推荐给这个用户。这个问题对encoder-decoder架构来说简直易如反掌:先用MLP将两ID变成一个向量,再用RNN把这个向量解码成一段文本。但我们想用Transformer来做生成,因为它拥有比RNN更强大的语言建模能力。然而,直接把用户ID、产品ID和单词拼在一起作为一个序列送到Transformer里,会使得模型对任意一对用户-产品生成的解释一模一样。为了更加直观地理解这个问题,我们来看看模型里的注意力权重(图1最左边两列),越白表示权重越大。我们可以看到,模型完全不根据用户和产品ID来做生成,而是依据<bos>这个特殊符号,难怪每个句子都一样的!
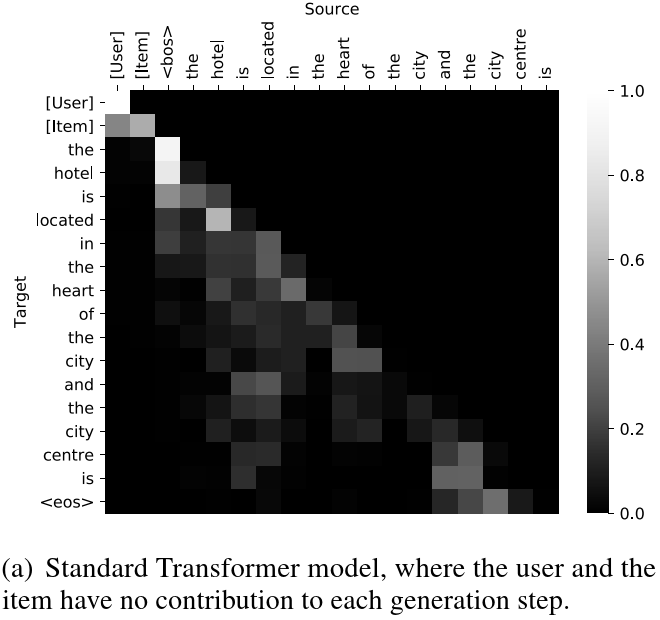 Figure 1: 注意力权重可视化.
Figure 1: 注意力权重可视化.
缘由
为什么会产生这种情况呢?试想在某宝某东这样大的电商平台上,用户数量和产品数量得上亿,但是用户写的点评里也就三千种常用的汉字(其他语言大同小异),这就使得ID和单词出现的频率非常不匹配(前者频率低,后者频率高),导致模型将ID视作词表外的词(OOV token),因此模型对ID完全不敏感。
方案
知道了原因后(其实是做了大量实验才恍然大悟),我们设计了一个简单但是非常巧妙的任务来连接ID和单词:用产品ID对应位置(用户ID亦可)的向量来预测需要被生成的单词(见图2)。注意,这里说的预测不是一步一步生成,而是在这一个位置预测出解释文本里所有的词。通过这样一个任务,我们就可以很好地将ID和单词联系起来了。
为了使这个模型尽善尽美,我们还用用户ID对应的向量进行评分预测,即推荐。为了实现这个想法,我们对Transformer的注意力矩阵做了一个小小的改动,使得用户ID和产品ID对应的位置可以互相访问(图2橙色线),但其他用于生成解释的位置只能访问它自己及它左边的位置(图2蓝色线)。另外,用户可能会主动要求系统解释推荐的产品的某些特征,为了满足这样的需求,我们把这些特征拼接到ID后面来做生成(对应图2的可选位置),记作PETER+,这样可以生成更有针对性的解释。
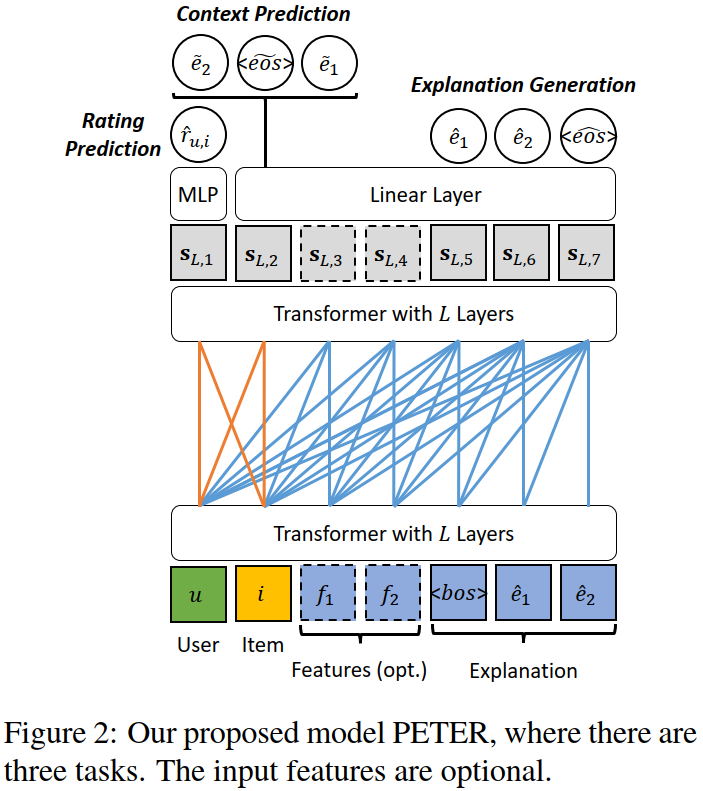 Figure 2: 模型的基本结构.
Figure 2: 模型的基本结构.
结果
从图3最左边两列我们可以看到,我们的模型在生成解释的过程中会有效地利用用户ID和产品ID,达到个性化生成的目的。
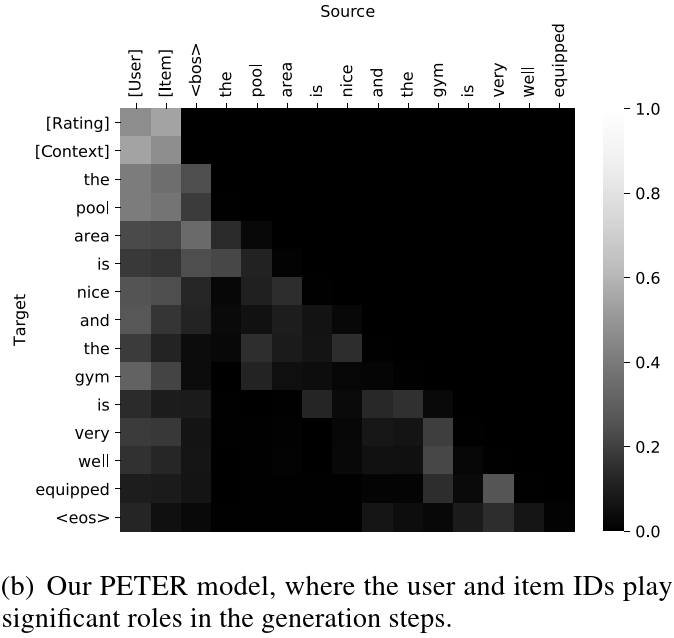 Figure 3: 有效融入ID后的模型注意力权重可视化.
Figure 3: 有效融入ID后的模型注意力权重可视化.
另外,把连接ID和单词这个任务的预测结果(图4左)跟生成的解释(图4右)进行对比,可以看出这个任务确实能赋予ID以一定语言学意义。预测出来的词之所以是乱序的,是因为它们是从同一个位置出来的,一开始就没有语序要求。里面除了高频词(如the)之外,还会包含一些产品特征,而最终生成的解释则是在描述这些特征。
 Figure 4: 预测的情境词和生成的解释.
Figure 4: 预测的情境词和生成的解释.
意义
- 从小的方面讲,凡是希望通过Transformer来实现个性化生成的应用(如个性化的聊天机器人)都可以借鉴我们设计的任务。
- 从大的方面讲,我们将异质输入(ID和单词)联系起来的思路对于多模态人工智能(如DALL**·**E中的图片和文本)也有一定参考价值。
- 另外,我们的Transformer非常小,只有两层,对于学术用途相当友好。给当前火热的预训练提供一个新思路:与其盲目的堆算力和语料,倒不如设计一些恰当的任务。
展望
上述将这个模型用于个性化的聊天机器人以及用户评论摘要的想法都是触手可及的,刚入学的同学可以拿来练练手。为了开源,我们的代码整理得还是相当规范的。相对于文本,事实上图片所包含的信息更大,有道是“一图胜千言”。如在找餐厅或者酒店的过程中,人都倾向于看图而不是描述。因此,我们后来又在这个工作的基础上尝试了图片生成,感兴趣可以查看下面这篇论文。
- Shijie Geng, Zuohui Fu, Yingqiang Ge, Lei Li, Gerard de Melo, Yongfeng Zhang. Improving Personalized Explanation Generation through Visualization. ACL'22. [Paper]
顺便提一下,这个工作是我们前面一个工作的延续,因此用到了里面的数据集和评估指标。但两个工作采用了完全不一样的模型架构,创作的动机也不同。感兴趣可以访问下面这个链接。