刚打造的小生态NLG4RS:基于推荐系统的自然语言生成
Author: Lei LI
Department of Computer Science, Hong Kong Baptist University
该生态(链接)包括:典型自然语言生成模型的PyTorch实现(预训练模型GPT-2、Transformer、GRU和LSTM),评估指标,公开数据集,以及创建这些数据集的代码。应用场景以推荐系统解释生成(recommendation explanation generation)为例,但不局限于此,可扩展至其他相似应用,如用户评论生成(review generation)、用户评论摘要(review summarization)、提示生成(tip generation)、对话系统(dialogue systems)等。
创建动机
对于身在科研一线的朋友们来说,算法和模型的实现/复现有时候比idea还重要。往往一个参数设置的差异,就会导致极不理想的实验结果。就拿PyTorch官方给的Transformer教程来说,里头把gradient clipping设为0.25,极大地限制了模型的梯度更新,进一步限制了模型的学习能力,导致最后生成的文本全是逗号(最高频词)。本人花了大概两三个星期才整明白问题出在哪里(观光链接)。这样的开源项目,无疑会给科研人员造成困扰,同时还会耗费很多时间。另外,有的论文即使开源了代码,但由于实现的时间较早,用的都是上古时代的深度学习框架(如Theano和Torch),跟当前热门的深度学习框架(如PyTorch和TensorFlow)不兼容,需要一定的学习成本。同时,即使是用同一个框架实现的,每个人写代码的风格也千差万别。考虑到这些问题,本人决定把自己实现/复现的自然语言生成模型(可以跑出不错效果)“打包”开源出来,以促进相关领域的发展,同时推广我们自己的工作。
有人可能会问:为什么不开发一套框架或者库?一则,本人时间精力水平都有限。二则,为了考虑通用性,框架或库的设计通常一个类嵌套着另一个类,如此往复(如huggingface的transformers库),增加了代码的阅读障碍。因此,本人不打算做成框架/库,甚至不会将这些模型放到同一个项目里。与此相反,只是在这里做一个总的介绍,大家可以访问感兴趣的模型项目链接,按照自己的需求灵活地添加各种功能。
问题定义
给定一个用户ID和一个物品ID,让模型生成一段文本(如图1)。在推荐解释生成的场景下,就是让模型解释为什么某个产品要推荐给某个用户。额外的数据(如知识图谱)这里暂不考虑,留给大家探索。
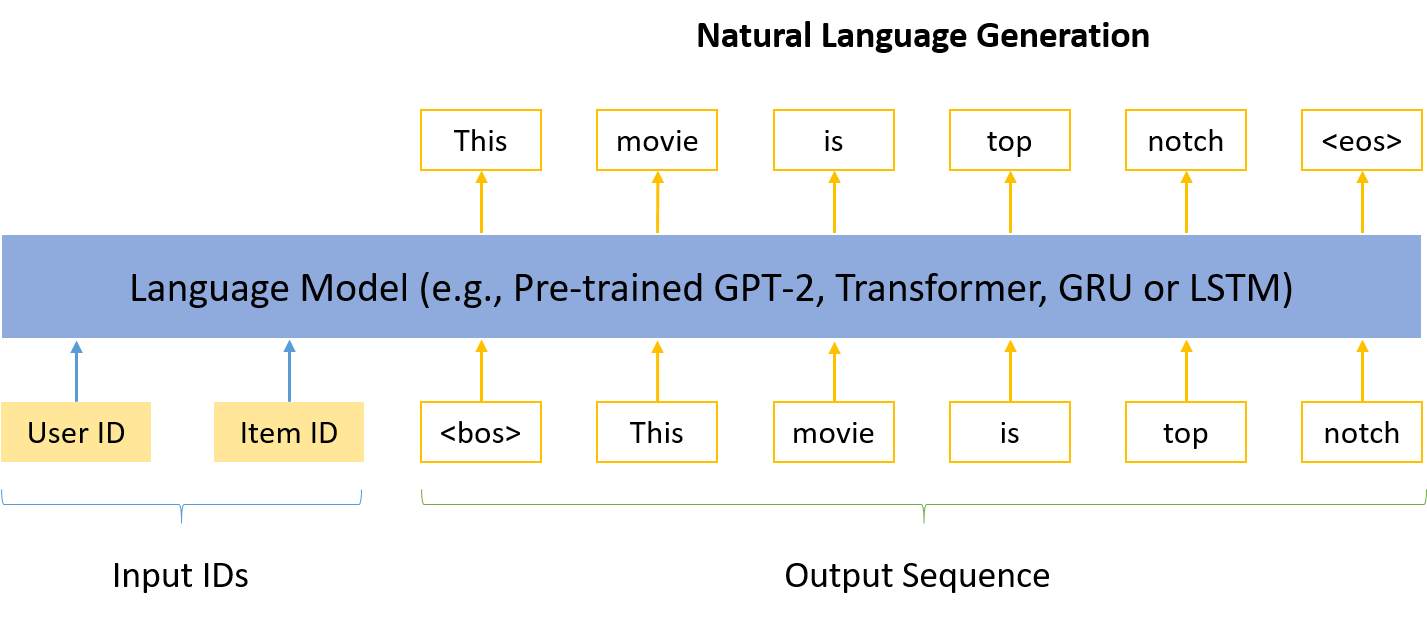 Figure 1: 基于推荐系统的自然语言生成.
Figure 1: 基于推荐系统的自然语言生成.
公开数据集及创建方法
很多工作将生成的用户评论直接当成推荐解释,我们认为这样是不合理的,因为不是评论里所有的句子都具备解释作用(比如“我昨天去了海底捞”就难以作为解释)。因此,我们的想法是从评论里抽出一些高质量的句子,这些句子包含用户对产品的某方面的评价(比如“这家日料的寿司很好吃”)。那如何得到这些句子呢?我们采用罗格斯大学张永锋老师在他PhD阶段开发的情感分析工具Sentires。这个工具可以从评论里抽出(feature,opinion,sentiment)三元组,比如日料那个句子可以得到(寿司,好吃,+1)。这个工具对于信息检索领域意义重大,因为很多工作都是基于它的结果做的。本人有个朋友就拿它来帮助构建知识图谱。
好用归好用,美中不足的是阅读文档来了解这个工具的学习成本并不低,普通人(譬如本人)没个几天时间压根拿不下来。另外,这个工具是用Java写的,但现在很多人更熟悉Python,如何把它们连接起来也是个问题。本人给这个工具套了一层Python的壳,由于一开始的目的是为了得到可以用作推荐解释的句子,丰富了功能,可以从评论中抽出(feature,opinion,sentiment,sentence)四元组。有了这个壳,研究人员可以不用花功夫去研究这个工具的文档,只需要改Python代码。送佛送到西,改哪一行本人都写好了。我们用这个工具总共创建了三个公开数据集(TripAdvisor Hong Kong、Amazon Movies & TV以及Yelp 2019)。原文及数据和代码链接如下:
Lei Li, Yongfeng Zhang, Li Chen. Generate Neural Template Explanations for Recommendation. CIKM'20. [Paper][Wrapper][Datasets]
Zhang, Yongfeng, et al. Do users rate or review? boost phrase-level sentiment labeling with review-level sentiment classification. SIGIR'14. [Paper][Toolkit]
评估指标
现有工作通常将机器翻译里的BLEU还有文本摘要里的ROUGE视作解释性的评价指标,我们认为这样是不全面的,因为它们更加侧重的是句子的可读性(通过跟参照文本进行对比),而不是解释性。比如,有的模型有时候会对不同的样本生成一模一样的句子,显然这样是不合理的,但是BLEU和ROUGE却没法反映出来。另外,对话系统中也常常会出现套话(universal reply)的情况,如“我不知道”和“好的”。为了定量评估这个问题,我们设计了一个评测句子多样性的指标USR。除此之外,我们还针对推荐系统的解释性提出了三个指标,用以评价句子里包含的产品属性(item feature)的匹配率FMR、覆盖率FCR和多样性DIV。这四个指标出自下面这个工作。它们并不完美,但代表我们对这个研究方向的一些思考。后面将要介绍的模型的实现中均配备这里提到的六大指标。
- Lei Li, Yongfeng Zhang, Li Chen. Generate Neural Template Explanations for Recommendation. CIKM'20. [Paper]
模型的PyTorch实现
以下简要介绍四个典型的基于推荐系统的自然语言生成模型,包括GPT-2、Transformer、GRU和LSTM。前两个是本人自己的工作,后两个是两位NLP大佬的工作(斗胆并列在一起)。模型全部用PyTorch 1.6实现/复现,代码风格相似,“举一反三”。
PEPLER (GPT-2)
这是本人近期的工作成果,已被ACM TOIS接收。在这个工作中,我们将ID作为提示(prompt)输入到预训练模型中,用以生成推荐解释。主要的难点是ID跟文本并不在同一个语义空间,同时大改预训练模型的结构也不太可能。受当前火热的提示学习(prompt learning)的启发,我们设计了两种方案:把ID替换成文本(离散提示学习),以及直接输入ID向量(连续提示学习)。对于后者,ID向量是随机初始化的,跟预训练过的模型处于不同的学习阶段,如何弥补它们之间的差距又是一个问题。为此我们进一步提出两种训练策略:把ID向量先训练一遍再跟预训练模型一起训练,以及将推荐任务作为解释任务的辅助正则项。此外没有添加任何其他花里胡哨的模块,但效果比下面要介绍的三个模型都好。
- Lei Li, Yongfeng Zhang, Li Chen. Personalized Prompt Learning for Explainable Recommendation. ACM Transactions on Information Systems (TOIS), 2023. [Paper][Code]
PETER (Transformer)
本人的另一个工作,采用的是普通的Transformer,同样是用ID来生成推荐解释。由于ID跟文本里的单词比起来过于稀疏,放到一起做attention会有问题(生成的句子高度重复),我们设计了一个额外的任务来连接ID和单词,赋予ID以语言学含义。除了生成解释外,该模型还可以做评分预测(即推荐)。
- Lei Li, Yongfeng Zhang, Li Chen. Personalized Transformer for Explainable Recommendation. ACL'21. [Paper][Code]
NRT (GRU)
本人复现的南京航空航天大学李丕绩教授的一个工作。这个工作在推荐系统领域很火,有230+引用。本人刚开始读PhD时读到这篇论文简直醍醐灌顶:模型简洁优雅,文中对推荐系统和自然语言生成两个任务都有非常独到的见解。自然语言生成部分采用的是编码器解码器结构,先用MLP将ID转化成一个向量,再用GRU解码成一段文本。推荐部分采用MLP预测一个评分。最后多个任务(还有一个评论预测被本人去掉了)放到一个多任务学习框架上一起优化。
- Li, Piji, et al. Neural Rating Regression with Abstractive Tips Generation for Recommendation. SIGIR'17. [Paper][Code-theano][Code-pytorch]
Att2Seq (LSTM)
本人复现的微软亚洲研究院董力博士早期的一个工作。这个工作现在在推荐系统领域也很火,有140+引用,无论是做评论生成还是解释生成都会拿它来做baseline。模型也是类似的编码器解码器结构,用MLP将ID转化成一个向量,再用一个两层的LSTM解码成一段文本。
- Dong, Li, et al. Learning to Generate Product Reviews from Attributes. EACL'17. [Paper][Code-torch][Code-pytorch]