ACM TIST 2023 & SIGIR 2021 | 像搜索引擎一样给推荐物品的解释进行排序
Author: Lei LI
Department of Computer Science, Hong Kong Baptist University
- Lei Li, Yongfeng Zhang, Li Chen. On the Relationship between Explanation and Recommendation: Learning to Rank Explanations for Improved Performance. ACM Transactions on Intelligent Systems and Technology (TIST), 2023. [Paper][Code]
- Lei Li, Yongfeng Zhang, Li Chen. EXTRA: Explanation Ranking Datasets for Explainable Recommendation. SIGIR'21. [Paper][Code][Datasets]
简介
向用户解释为什么系统会推荐某些物品至关重要,因为它可以帮助用户做出更好的决策,提高他们的满意度,还可以获得他们对推荐系统的信任。因而,可解释推荐系统的研究得到了学术界和工业界的广泛关注,产生了各种各样的模型。但它们的评估方法因模型而异,这就使得不同模型之间的对比变得异常困难。为了实现一种统一的推荐解释评估方法,我们创建了一套名为EXTRA的数据集。在这套数据集上,推荐可解释性可以通过面向排序的指标来评估,如NDCG。基本思想是训练一个模型,让它从众多解释中选出一些比较恰当的来解释推荐的物品。
有了这套数据集,我们进而将传统的物品排序扩展成物品-解释联合排序,用以研究刻意选一些解释是否可以达到某些目标,如提高推荐准确度。有个难点是,用户-物品-解释三元组数据的稀疏性不可避免地比传统的用户-物品二元组数据严重,因为并非每对用户-物品都与所有解释相关联。为了解决这个问题,我们将用户-物品-解释三元组看作两个二元组来分别进行矩阵分解。基于这个想法,我们设计了两种模型。其一是仅使用ID的模型,在未来它或许可以用在其他类型的解释上,例如图像。其二是基于BERT的模型,它可以利用解释文本的语义特征来提高排序性能。
搜索引擎vs.解释排序
搜索引擎(如Google和Bing)是人们日常生活中获取信息的一种常用工具。当用户给搜索引擎输入一个关键词(如“苹果”),它会返回成千上万的网页(如“苹果公司”和“水果苹果”),用户则可以根据自己的兴趣和需求点击查看相应的页面(如图1)。
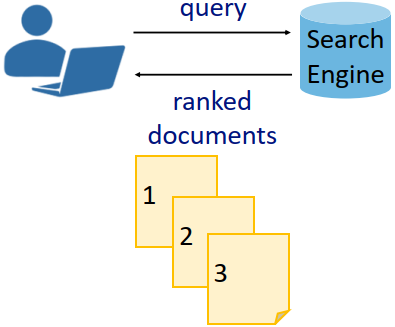 Figure 1: 搜索引擎.
Figure 1: 搜索引擎.
受搜索引擎的启发,我们认为推荐物品的解释也是可以排序的(如图2)。我们首先准备很多解释条目,再让推荐系统解释模型去给不同用户-物品返回恰当的解释。举例来说,当一个电影推荐系统(如豆瓣)给用户推荐电影《冰雪奇缘》时,它可以提供这些解释:“适合和家人一起看”、“动画效果优良”、“故事讲得好”。这些解释一开始就存在,只不过针对不同的电影和用户,返回的解释不一样。有了包含这些解释的数据集,研究人员的重心就可以放在如何设计出更好的排序算法上。
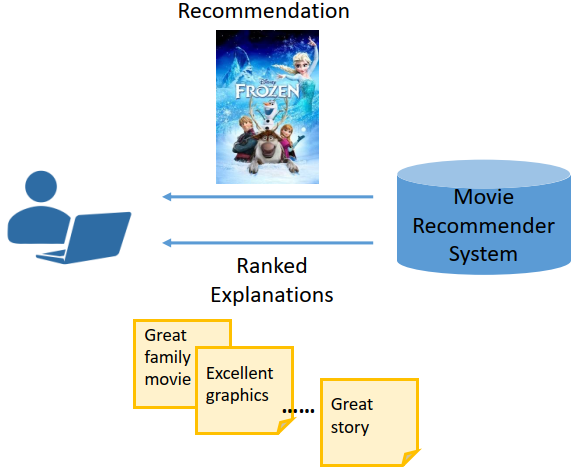 Figure 2: 解释排序.
Figure 2: 解释排序.
数据集创建
构建数据集也遇到了一些挑战。首先,用户-物品-解释三元组在现有的推荐系统中很少见,因此如何找到替代方案是一个问题。受群体智慧的启发,我们的解决方案是把各个用户评论中共同出现的句子抽取出来作为解释(如图3),以便将不同的用户-物品组合与某一个特定的解释联系起来,这样就可以创建出用户-物品-解释三元组数据了(如图4)。通过找出评论中常用的句子,也可以保证解释的可读性和表达性。
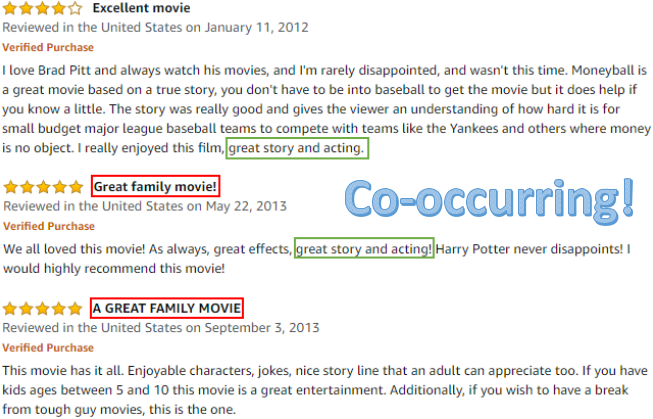 Figure 3: 不同用户评论中重复的句子.
Figure 3: 不同用户评论中重复的句子.
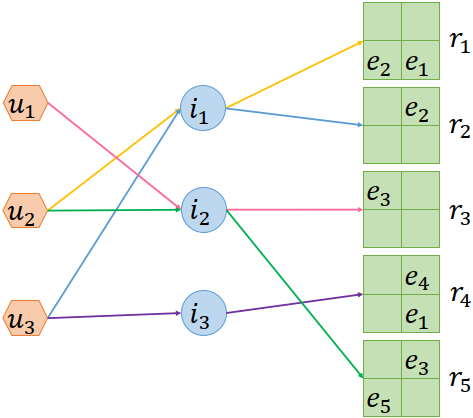 Figure 4: 用户-物品-解释三元组交互数据.
Figure 4: 用户-物品-解释三元组交互数据.
这个方案带来了第二个挑战,即如何在一个数据集的评论中检测出几乎相同的句子。聚类是不可行的,因为它需要预先定义类别的数量。计算数据集中任意两个句子之间的相似度是可行的,但效率较低,因为它的时间复杂度是。但在句子分组的每一步,实际上没有必要计算已经分好了组的句子的相似度。因此,我们可以移除这些句子来降低计算成本。为了进一步提高效率,我们采用了局部敏感哈希 (LSH) 方法(如图5),它可以在亚线性时间内检测出重复文本。
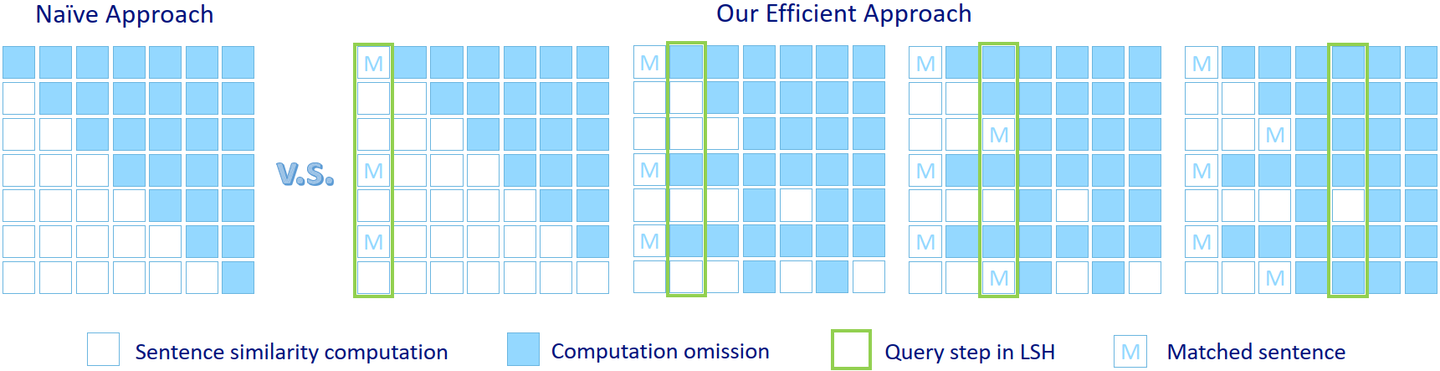 Figure 5: 针对重复句子检测,普通方法同我们提出的方法之间的效率对比.
Figure 5: 针对重复句子检测,普通方法同我们提出的方法之间的效率对比.
我们基于Amazon Movies & TV,TripAdvisor和Yelp创建了三个数据集。同时也公开了数据创建的代码,这样其他研究人员也可以根据需求创建自己的数据集。图6是数据集中解释的例子,可以看出它们都能较好地反映出相应领域的特点。
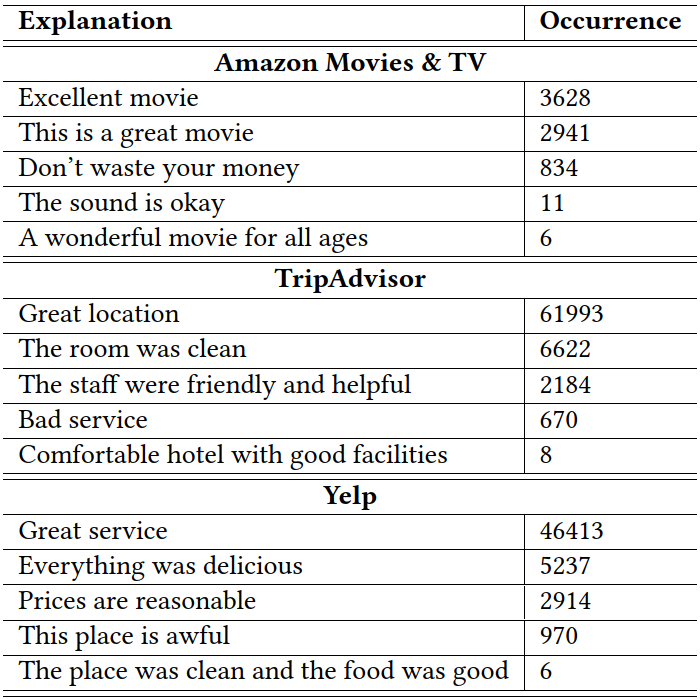 Figure 6: 三个数据集中解释的例子.
Figure 6: 三个数据集中解释的例子.
问题定义
物品排序
在传统的推荐场景中,给定一个用户u,推荐系统会给所有物品进行排序,返回一定数量的分值较高的物品(如M个),可以用如下公式表示:
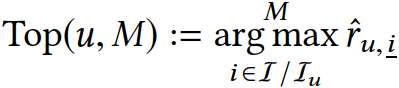
解释排序
在我们提出的解释排序问题中,用户u和物品i都是给定的(既可以是用户自己的行为,也可以是推荐模型预测出来的),推荐系统会给所有解释进行排序,然后返回一定数量的分值较高的解释(如N个):
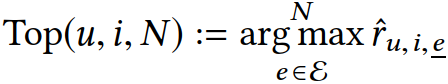
模型
由于解释排序的数据是用户-物品-解释三元组的形式,人们很自然会想到张量分解方法。其中一种典型的方法是将这三种实体的向量相乘得到一个标量:
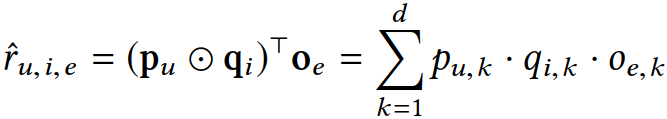
在我们的数据中,每对用户-物品不可能跟所有解释都有关联,因此数据的稀疏性就比传统的物品排序数据大很多。由于数据的稀疏性,张量分解方法不一定有效。为了解决这个问题,我们将张量分解拆分成两组矩阵分解。这样用户-物品-解释三元组就变成了用户-解释及物品-解释两个两元组了,类似于传统推荐中的用户-物品二元组。我们把该方法命名为BPER。
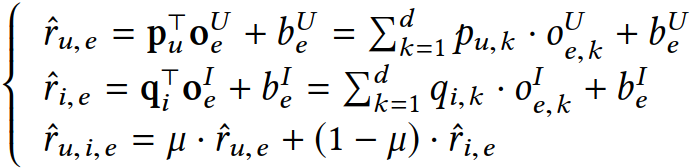
上面这种方法只用到了ID信息。除此之外,解释文本的语义信息亦可提高模型的排序性能。举例来说,对于推荐电影的解释,“表演很棒”和“表演不错”意思差不多,因而它们在排序列表里的位置也应该差不多。但是仅采用ID的方法可能无法有效区分二者。因此,我们进而探索解释文本是否有助于提高排序效果。我们用BERT来提取解释文本中的语义信息,得到的向量用于增强解释ID对应的向量。该方法记作BPER+。
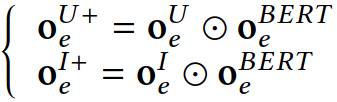
作为第一个对推荐解释进行排序的工作,为了达到可复现性的目的,我们把两种方法都设计得相对简单。
为了进一步探究刻意选出某些解释是否可以同时提高推荐和解释的效果,我们将物品和解释进行联合排序。具体来说,我们将推荐任务的目标函数和解释的目标函数融入到一个多任务学习的框架中。
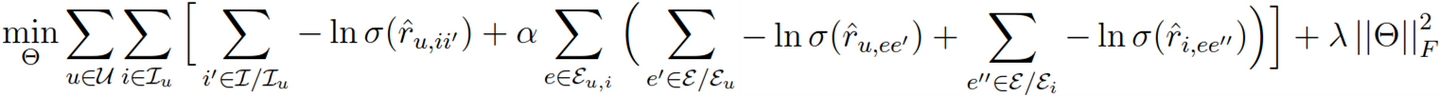
结果
图7的结果显示,在只用到ID时,我们的方法比传统的协同过滤和张量分解表现都要好。在加上解释文本的语义信息之后,解释排序效果变得更好了,尤其是在NDCG上。
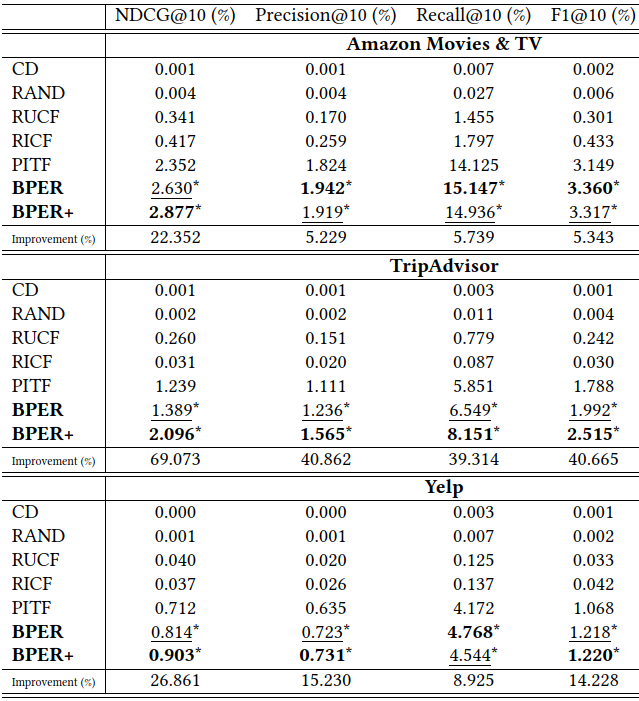 Figure 7: 解释排序实验结果.
Figure 7: 解释排序实验结果.
另外,对于物品-解释联合排序,在一些情况下(图8绿框),推荐和解释效果可以同时得到提高。
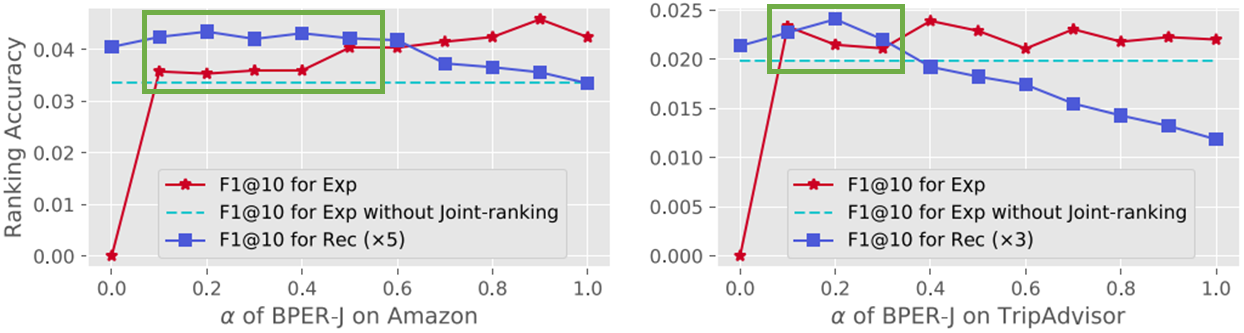 Figure 8: 物品-解释联合排序.
Figure 8: 物品-解释联合排序.
展望
把文本扩展到图像上从而实现多模态推荐解释排序,会是一个有趣的课题。同时,如果能跟工业界合作做一个线上测试,可以了解这些解释会对真实用户产生哪些影响。另外,我们对于推荐解释涉及的道德层面的问题也有很大兴趣。譬如,我们让模型刻意选出某些解释来提高推荐效果,会不会导致推荐物品没有解释里描述得那么好?更深层次的问题是,这些解释在诱导用户点击和购买时会不会欺骗用户?这就会造成人与机器之间的信任问题了。
